手把手教你采集京东销售数据并做简单的数据分析和可视化
前言
大家好!我是古月星辰,大三本科生,数学专业,Python爬虫爱好者一枚。今天给大家带来JD数据的简单采集和可视化分析,希望大家可以喜欢。

一、目标数据
随着移动支付的普及,电商网站不断涌现,由于电商网站产品太多,由用户产生的评论数据就更多了,这次我们以京东为例,针对某一单品的评论数据进行数据采集,并且做简单数据分析。
二、页面分析
这个是某一手机页面的详情页,对应着手机的各种参数以及用户评论信息,页面URL是:
https://item.jd.com/10022971060622.html#none
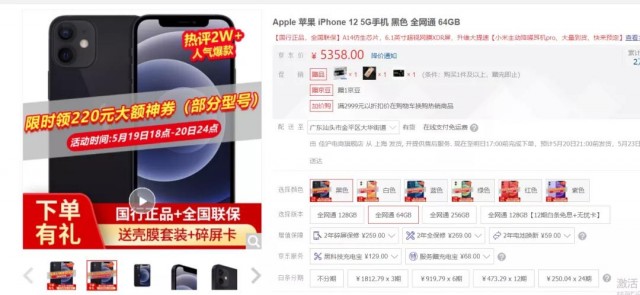
然后通过分析找到评论数据对应的数据接口,如下图所示:
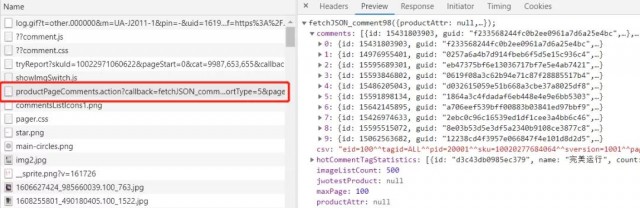
它的请求url:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_com ment98& productId=10022971060622 &score=0&sortType=5& page=0 &pageSize=10&isShadowSk u=0&fold=1
注意看到这两个关键参数
1. productId: 每个商品有一个id
2. page: 对应的评论分页
三、解析数据
对评论数据的url发起请求:
url:https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comm ent98& productId=10022971060622 &score=0&sortType=5& page=0 &pageSize=10&isShado wSku=0&fold=1
json.cn 打开json数据(我们的评论数据是以json形式与页面进行交互传输的),如下图所示:
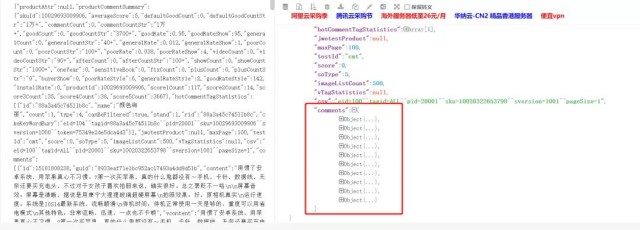
分析可知,评论url中对应十条评论数据,对于每一条评论数据,我们需要获取3条数
据,contents,color,size(注意到上图的maxsize,100,也就是100*10=1000条评论)。
四、程序 1.导入相关库 import requests import json import time import openpyxl #第三方模块,用于操作Excel文件的 #模拟浏览器发送请求并获取响应结果 import random 2.获取评论数据 def get_comments(productId,page): url=https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1.format(productId,page) # 商品id resp=requests.get(url,headers=headers) #print(resp.text) #响应结果进行显示输出 s1=resp.text.replace(fetchJSON_comment98(,) #fetchJSON_comment98( s=s1.replace();,) #将str类型的数据转成json格式的数据 # print(s,type(s)) # print(**100) res=json.loads(s) print(type(res)) return res 3.获取最大页数(也可以不写) def get_max_page(productId): dic_data=get_comments(productId,0) #调用刚才写的函数,向服务器发送请求,获取字典数据 return dic_data[maxPage] 4.提取数据 def get_info(productId): #调用函数获取商品的最大评论页数 #max_page=get_max_page(productId) # max_page=10 lst=[] #用于存储提取到的商品数据 for page in range(0,get_max_page(productId)): #循环执行次数 #获取每页的商品评论 comments=get_comments(productId,page) comm_lst=comments[comments] #根据key获取value,根据comments获取到评论的列表(每页有10条评论) #遍历评论列表,分别获取每条评论的中的内容,颜色,鞋码 for item in comm_lst: #每条评论又分别是一个字典,再继续根据key获取值 content=item[content] #获取评论中的内容 color=item[productColor] #获取评论中的颜色 size=item[productSize] #鞋码 lst.append([content,color,size]) #将每条评论的信息添加到列表中 time.sleep(3) #延迟时间,防止程序执行速度太快,被封IP save(lst) #调用自己编写的函数,将列表中的数据进行存储 5.用于将爬取到的数据存储到Excel中 def save(lst): wk=openpyxl.Workbook () #创建工作薄对象 sheet=wk.active #获取活动表 #遍历列表,将列表中的数据添加到工作表中,列表中的一条数据,在Excel中是 一行 for item in lst: sheet.append(item) #保存到磁盘上 wk.save(销售数据.xlsx) 6.运行程序 if __name__ == __main__: productId=10029693009906 # 单品id get_info(productId)
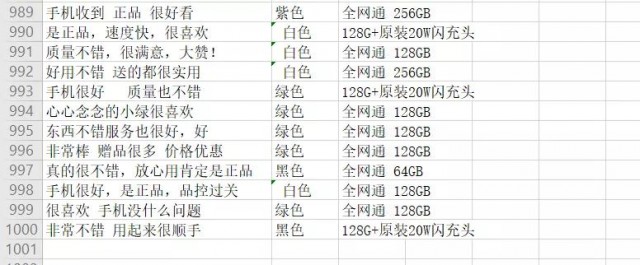
五、简单数据 1.简单配置 # 导入相关库 import pandas as pd import matplotlib.pyplot as plt # 这两行代码解决 plt 中文显示的问题 plt.rcParams[font.sans-serif] = [SimHei] plt.rcParams[axes.unicode_minus] = False # 由于采集的时候没有设置表头,此处设置表头 data = pd.read_excel(./销售数据.xlsx, header=None, names = [comments,color,intro] ) # data.head()

2.手机颜色数量对比 x = [白色,黑色,绿色,
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录