这20个Pandas函数,堪称”数据清洗”杀手!
今天准备介绍一篇超级肝货!
Pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。它提供了大量能使我们快速便捷地处理数据的函数和方法。
本文介绍的这20个【被分成了15组】函数,绝对是数据处理杀手,用了你会爱不释手。
构造数据集
这里为大家先构造一个数据集,用于为大家演示这20个函数。
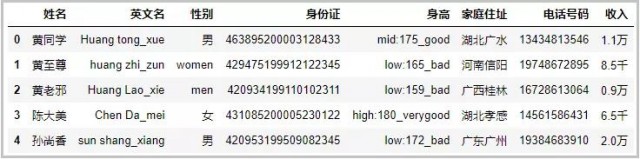
import pandas as pd df ={姓名:[ 黄同学,黄至尊,黄老邪 ,陈大美,孙尚香], 英文名:[Huang tong_xue,huang zhi_zun,Huang Lao_xie,Chen Da_mei,sun shang_xiang], 性别:[男,women,men,Ů,男], 身份证:[463895200003128433,429475199912122345,420934199110102311,431085200005230122,420953199509082345], 身高:[mid:175_good,low:165_bad,low:159_bad,high:180_verygood,low:172_bad], 家庭住址:[湖北广水,河南信阳,广西桂林,湖北孝感,广东广州], 电话号码:[13434813546,19748672895,16728613064,14561586431,19384683910], 收入:[1.1万,8.5ǧ,0.9万,6.5ǧ,2.0万]} df = pd.DataFrame(df) df
效果图:
1. cat函数
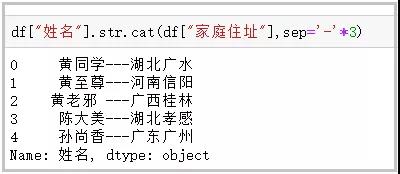
这个函数主要用于字符串的拼接;
df[“姓名”].str.cat(df[“家庭住址”],sep=-*3)
效果图:
2. contains函数
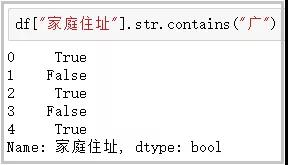
这个函数主要用于判断某个字符串是否包含给定字符;
df[“家庭住址”].str.contains(“广”)
效果图:
3. startswith、endswith函数
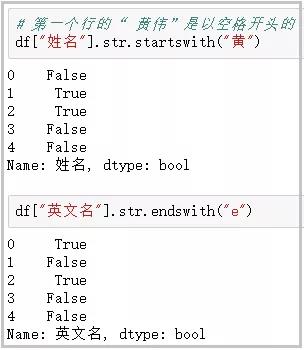
这个函数主要用于判断某个字符串是否以…开头/结尾;
# 第一个行的“ 黄伟”是以空格开头的 df[“姓名”].str.startswith(“黄”) df[“英文名”].str.endswith(“e”)
效果图:
4. count函数
这个函数主要用于计算给定字符在字符串中出现的次数;
df[“电话号码”].str.count(“3”)
效果图:

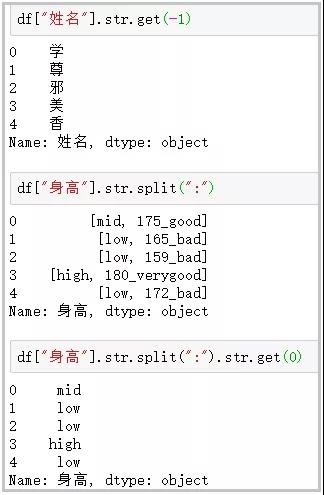
5. get函数
这个函数主要用于获取指定位置的字符串;
df[“姓名”].str.get(-1) df[“身高”].str.split(“:”) df[“身高”].str.split(“:”).str.get(0)
效果图:
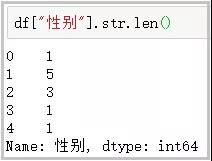
6. len函数
这个函数主要用于计算字符串长度;
df[“性别”].str.len()
效果图:
7. upper、lower函数
这个函数主要用于英文大小写转换;
df[“英文名”].str.upper() df[“英文名”].str.lower()
效果图:

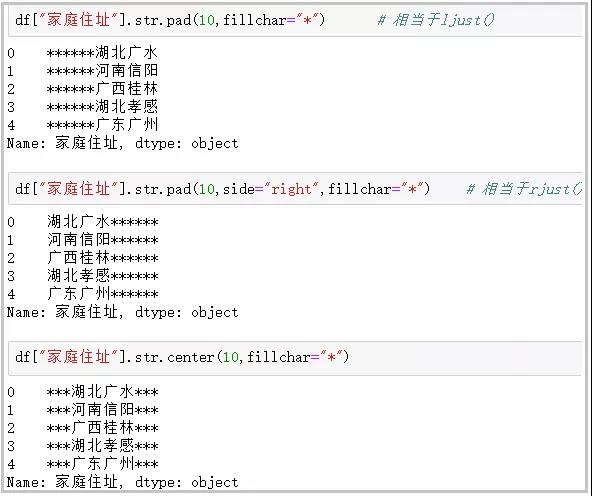
8. pad+side参数/center函数
这个函数主要用于在字符串的左边、右边或左右两边添加给定字符;
df[“家庭住址”].str.pad(10,fillchar=”*”) # 相当于ljust() df[“家庭住址”].str.pad(10,side=”right”,fillchar=”*”) # 相当于rjust() df[“家庭住址”].str.center(10,fillchar=”*”)
效果图:
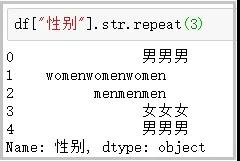
9. repeat函数
这个函数主要用于重复字符串几次;
df[“性别”].str.repeat(3)
效果图:
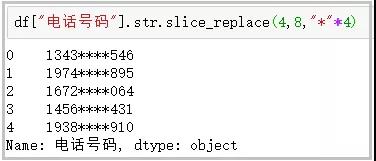
10. slice_replace函数
这个函数主要用于使用给定的字符串,替换指定的位置的字符;
df[“电话号码”].str.slice_replace(4,8,”*”*4)
效果图:
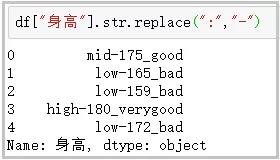
11. replace函数
这个函数主要用于将指定位置的字符,替换为给定的字符串;
df[“身高”].str.replace(“:”,”-“)
效果图:
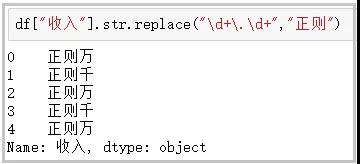
这个函数还接受正则表达式,将指定位置的字符,替换为给定的字符串。
df[“收入”].str.replace(“d+.d+”,”正则”)
效果图:
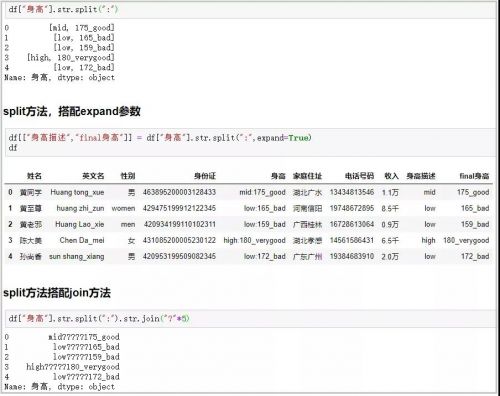
12. split方法+expand参数
这个函数主要用于将一列扩展为好几列;
# 普通用法 df[“身高”].str.split(“:”) # split方法,搭配expand参数 df[[“身高描述”,”final身高”]] = df[“身高”].str.split(“:”,expand=True) df # split方法搭配join方法 df[“身高”].str.split(“:”).str.join(“?”*5)
效果图:
13. strip、rstrip、lstrip函数
这个函数主要用于去除空白符、换行符;
df[“姓名”].str.len() df[“姓名”] = df[“姓名”].str.strip() df[“姓名”].str.len()
效果图:
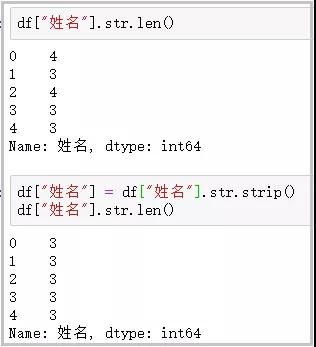
14. findall函数
这个函数主要用于利用正则表达式,去字符串中匹配,返回查找结果的列表;
df[“身高”] df[“身高”].str.findall(“[a-zA-Z]+”)
效果图:
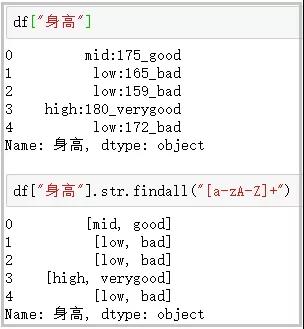
15. extract、extractall函数
这个函数主要用于接受正则表达式,抽取匹配的字符串(一定要加上括号);
df[“身高”].str.extract(“([a-zA-Z]+)”) # extractall提取得到复合索引 df[“身高”].str.extractall(“([a-zA-Z]+)”) # extract搭配expand参数 df[“身高”].str.extract(“([a-zA-Z]+).*?([a-zA-Z]+)”,expand=True)
效果图:
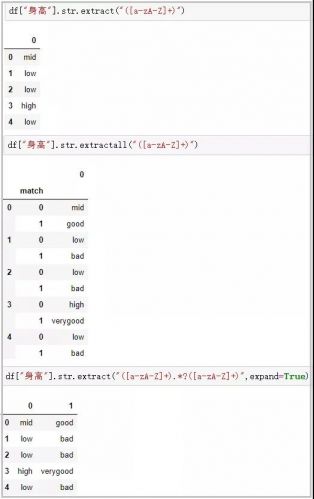
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录