比用Pytorch框架快200倍!0.76秒后,笔记本上的CNN就搞定了MNIST
本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
在MNIST上进行训练,可以说是计算机视觉里的“Hello World”任务了。
而如果使用PyTorch的标准代码训练CNN,一般需要3分钟左右。
但现在,在一台笔记本电脑上就能将时间缩短200多倍。
速度直达0.76秒!
那么,到底是如何仅在一次epoch的训练中就达到99%的准确率的呢?
八步提速200倍
这是一台装有GeForce GTX 1660 Ti GPU的笔记本。
我们需要的还有Python3.x和Pytorch 1.8。
先下载数据集进行训练,每次运行训练14个epoch。
这时两次运行的平均准确率在测试集上为99.185%,平均运行时间为2min 52s ± 38.1ms。
接下来,就是一步一步来减少训练时间:
 一、提前停止训练
一、提前停止训练
在经历3到5个epoch,测试准确率达到99%时就提前停止训练。
这时的训练时间就减少了1/3左右,达到了57.4s±6.85s。
二、缩小网络规模,采用正则化的技巧来加快收敛速度
具体的,在第一个conv层之后添加一个2×2的最大采样层(max pool layer),将全连接层的参数减少4倍以上。
然后再将2个dropout层删掉一个。
这样,需要收敛的epoch数就降到了3个以下,训练时间也减少到30.3s±5.28s。
三、优化数据加载
使用data_loader.save_data(),将整个数据集以之前的处理方式保存到磁盘的一个pytorch数组中。
也就是不再一次一次地从磁盘上读取数据,而是将整个数据集一次性加载并保存到GPU内存中。
这时,我们只需要一次epoch,就能将平均训练时间下降到7.31s ± 1.36s。
四、增加Batch Size
将Batch Size从64增加到128,平均训练时间减少到4.66s ± 583ms。
五、提高学习率
使用Superconvergence来代替指数衰减。
在训练开始时学习率为0,到中期线性地最高值(4.0),再慢慢地降到0。
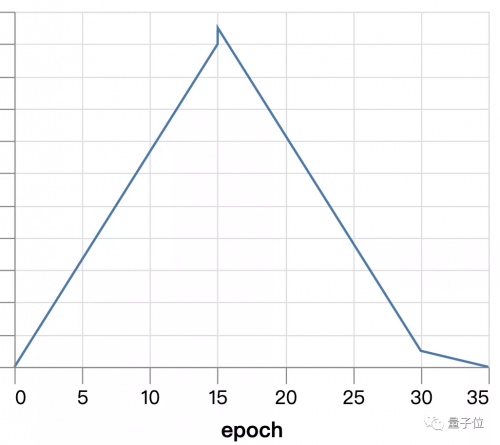
这使得我们的训练时间下降到3.14s±4.72ms。
六、再次增加Batch Size、缩小缩小网络规模
重复第二步,将Batch Size增加到256。
重复第四步,去掉剩余的dropout层,并通过减少卷积层的宽度来进行补偿。
最终将平均时间降到1.74s±18.3ms。
七、最后的微调
首先,将最大采样层移到线性整流函数(ReLU)激活之前。
然后,将卷积核大小从3增加到5.
最后进行超参数调整:
使学习率为0.01(默认为0.001),beta1为0.7(默认为0.9),bata2为0.9(默认为0.999)。
到这时,我们的训练已经减少到一个epoch,在762ms±24.9ms的时间内达到了99.04%的准确率。

“这只是一个Hello World案例”
对于这最后的结果,有人觉得司空见惯:
优化数据加载时间,缩小模型尺寸,使用ADAM而不是SGD等等,都是常识性的事情。
我想没有人会真的费心去加速运行MNIST,因为这是机器学习中的“Hello World”,重点只是像你展示最小的关键值,让你熟悉这个框架——事实上3分钟也并不长吧。

而也有网友觉得,大多数人的工作都不在像是MNIST这样的超级集群上。因此他表示:
我所希望的是工作更多地集中在真正最小化训练时间方面。

GitHub:https://github.com/tuomaso/train_mnist_fast
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录