用 Python 轻松实现机器学习
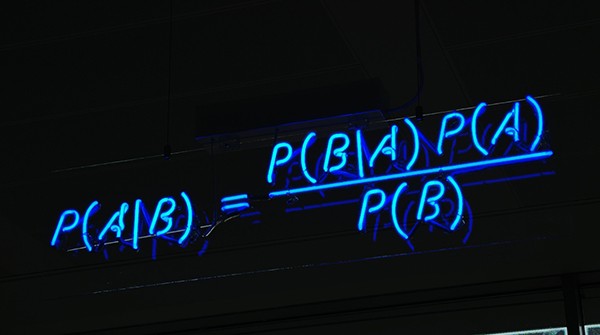
用朴素贝叶斯分类器解决现实世界里的机器学习问题。
朴素贝叶斯Naïve Bayes是一种分类技术,它是许多分类器建模算法的基础。基于朴素贝叶斯的分类器是简单、快速和易用的机器学习技术之一,而且在现实世界的应用中很有效。
朴素贝叶斯是从 贝叶斯定理Bayes theorem 发展来的。贝叶斯定理由 18 世纪的统计学家 托马斯·贝叶斯 提出,它根据与一个事件相关联的其他条件来计算该事件发生的概率。比如,帕金森氏病 患者通常嗓音会发生变化,因此嗓音变化就是与预测帕金森氏病相关联的症状。贝叶斯定理提供了计算目标事件发生概率的方法,而朴素贝叶斯是对该方法的推广和简化。
解决一个现实世界里的问题
这篇文章展示了朴素贝叶斯分类器解决现实世界问题(相对于完整的商业级应用)的能力。我会假设你对机器学习有基本的了解,所以文章里会跳过一些与机器学习预测不大相关的步骤,比如 数据打乱date shuffling 和 数据切片data splitting。如果你是机器学习方面的新手或者需要一个进修课程,请查看 《An introduction to machine learning today》 和 《Getting started with open source machine learning》。
朴素贝叶斯分类器是 有监督的supervised、属于 生成模型generative 的、非线性的、属于 参数模型parametric 的和 基于概率的probabilistic。
在这篇文章里,我会演示如何用朴素贝叶斯预测帕金森氏病。需要用到的数据集来自 UCI 机器学习库。这个数据集包含许多语音信号的指标,用于计算患帕金森氏病的可能性;在这个例子里我们将使用这些指标中的前 8 个:
MDVP:Fo(Hz):平均声带基频 MDVP:Fhi(Hz):最高声带基频 MDVP:Flo(Hz):最低声带基频 MDVP:Jitter(%)、MDVP:Jitter(Abs)、MDVP:RAP、MDVP:PPQ 和 Jitter:DDP:5 个衡量声带基频变化的指标
这个例子里用到的数据集,可以在我的 GitHub 仓库 里找到。数据集已经事先做了打乱和切片。
用 Python 实现机器学习
接下来我会用 Python 来解决这个问题。我用的软件是:
Python 3.8.2 Pandas 1.1.1 scikit-learn 0.22.2.post1
Python 有多个朴素贝叶斯分类器的实现,都是开源的,包括:
NLTK Naïve Bayes:基于标准的朴素贝叶斯算法,用于文本分类 NLTK Positive Naïve Bayes:NLTK Naïve Bayes 的变体,用于对只标注了一部分的训练集进行二分类 Scikit-learn Gaussian Naïve Bayes:提供了部分拟合方法来支持数据流或很大的数据集(LCTT 译注:它们可能无法一次性导入内存,用部分拟合可以动态地增加数据) Scikit-learn Multinomial Naïve Bayes:针对离散型特征、实例计数、频率等作了优化 Scikit-learn Bernoulli Naïve Bayes:用于各个特征都是二元变量/布尔特征的情况
在这个例子里我将使用 sklearn Gaussian Naive Bayes。
我的 Python 实现在 naive_bayes_parkinsons.py 里,如下所示:
import pandas as pd # x_rows 是我们所使用的 8 个特征的列名x_rows=[MDVP:Fo(Hz),MDVP:Fhi(Hz),MDVP:Flo(Hz), MDVP:Jitter(%),MDVP:Jitter(Abs),MDVP:RAP,MDVP:PPQ,Jitter:DDP]y_rows=[status] # y_rows 是类别的列名,若患病,值为 1,若不患病,值为 0 # ѵ
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录