你写的ML代码占多少内存?这件事很重要,但很多人还不懂
在进行机器学习任务时,你需要学会使用代码快速检查模型的内存占用量。原因很简单,硬件资源是有限的,单个机器学习模块不应该占用系统的所有内存,这一点在边缘计算场景中尤其重要。
比如,你写了一个很棒的机器学习程序,或者搭建了一个不错的神经网络模型,然后想在某些 Web 服务或 REST API 上部署模型。或者你是基于工厂传感器的数据流开发了模型,计划将其部署在其中一台工业计算机上。
这时,你的模型可能是硬件上运行的几百个模型之一,所以你必须对内存占用峰值有所了解。否则多个模型同时达到了内存占用峰值,系统可能会崩溃。
因此,搞清楚代码运行时的内存配置文件(动态数量)非常重要。这与模型的大小和压缩均无关,可能是你事先已经将其保存在磁盘上的特殊对象,例如 Scikit-learn Joblib dump、Python Pickle dump,TensorFlow HFD5 等。
Scalene:简洁的内存 / CPU/GPU 分析器
首先要讨论的是 Scalene,它是一个 Python 的高性能 CPU 和内存分析器,由马萨诸塞大学研发。其 GitHub 页面是这样介绍的:「 Scalene 是适用于 Python 的高性能 CPU、GPU 和内存分析器,它可以执行许多其他 Python 分析器无法做到的事情,提供详细信息比其他分析器快几个数量级。」
安装
它是一个 Python 包,所以按照通常方法安装:
pip install scalene
这样适用于 Linux OS,作者没有在 Windows 10 上进行测试。
在 CLI 或 Jupyter Notebook 内部使用
Scalene 的使用非常简单:
scalene
也可以使用魔术命令在 Jupyter notebook 中使用它:
%load_ext scalene
输出示例
下面是一个输出示例。稍后将对此进行更深入的研究。
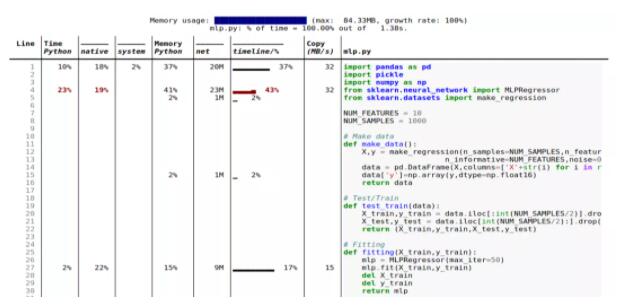
这些是 Scalene 一些很酷的功能:
行和函数:报告有关整个函数和每个独立代码行的信息; 线程:支持 Python 线程; 多进程处理:支持使用 multiprocessing 库; Python 与 C 的时间:Scalene 用在 Python 与本机代码(例如库)上的时间; 系统时间:区分系统时间(例如,休眠或执行 I / O 操作); GPU:报告在英伟达 GPU 上使用的时间(如果有); 复制量:报告每秒要复制的数据量; 泄漏检测:自动查明可能造成内存泄漏的线路。 ML 代码具体示例
接下来看一下 Scalene 用于内存配置标准机器学习代码的工作。对三个模型使用 Scikit-learn 库,并利用其综合数据生成功能来创建数据集。
对比的是两种不同类型的 ML 模型:
多元线性回归模型; 具有相同数据集的深度神经网络模型。
线性回归模型
使用标准导入和 NUM_FEATURES 、 NUM_SMPLES 两个变量进行一些实验。
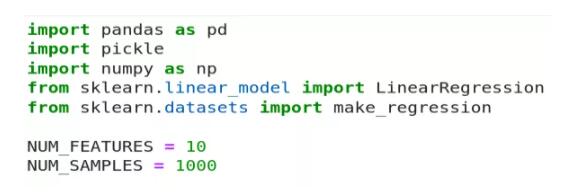
这里没有展示数据生成和模型拟合代码,它们是非常标准的。作者将拟合的模型另存为 pickled dump,并将其与测试 CSV 文件一起加载以进行推断。

为了清晰起见,将所有内容置于 Scalene 执行和报告环境下循环运行。

当运行命令时:
$ scalene linearmodel.py –html >> linearmodel-scalene.html
将这些结果作为输出。注意,此处使用了 –html 标志并将输出通过管道传输到 HTML 文件,以便于报告。
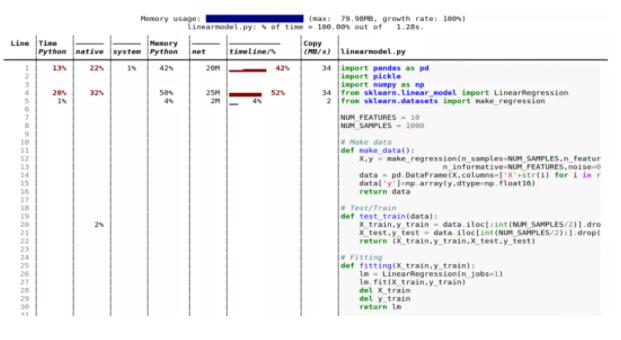
令人惊讶的是,内存占用几乎完全由外部 I / O(例如 Pandas 和 Scikit-learn estimator 加载)控制,少量会将测试数据写到磁盘上的 CSV 文件中。实际的 ML 建模、Numpy、Pandas 操作和推理,根本不会影响内存。
我们可以缩放数据集大小(行数)和模型复杂度(特征数),并运行相同的内存配置文件以记录各种操作在内存消耗方面的表现。结果显示在这里。
此处,X 轴代表特征 / 数据点集。注意该图描绘的是百分比,而不是绝对值,展示了各种类型操作的相对重要性。
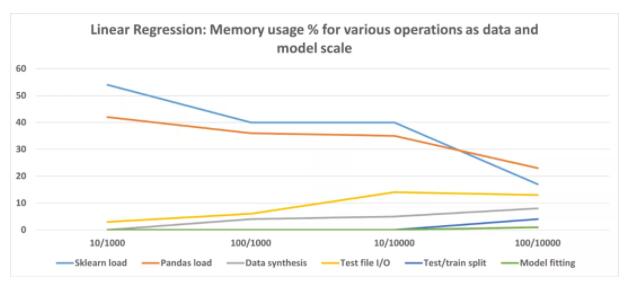
从这些实验中得出的结论是,Scikit-learn 线性回归估计非常高效,并且不会为实际模型拟合或推理消耗大量内存。
但就代码而言,它确实有固定的内存占用,并在加载时会消耗大量内存。不过随着数据大小和模型复杂性的增加,整个代码占用百分比会下降。如果使用这样的模型,则可能需要关注数据文件 I / O,优化代码以获得更好的内存性能。
深度神经网络如何?
如果我们使用 2 个隐藏层的神经网络(每个隐藏层有 50 个神经元)运行类似的实验,那么结果如下所示。
代码地址:https://github.com/tirthajyoti/Machine-Learning-with-Python/blob/master/Memory-profiling/Scalene/mlp.py
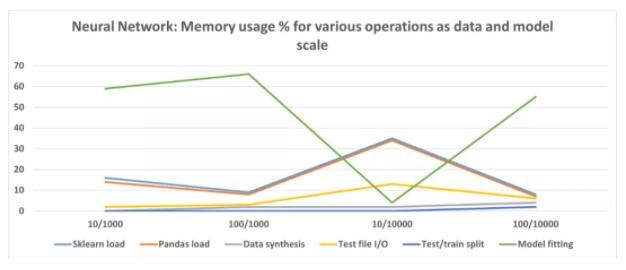
与线性回归模型不同,神经网络模型在训练 / 拟合步骤中消耗大量内存。但是,由于特征少且数据量大,拟合占用的内存较少。此外,还可以尝试各种体系结构和超参数,并记录内存使用情况,达到合适的设置。
复现说明
如果你使用相同的代码复现实验,结果可能会因硬件、磁盘 / CPU / GPU / 内存类型的不同而大相径庭。
一些关键建议
最好在代码中编写专注于单个任务的小型函数; 保留一些自由变量,例如特征数和数据点,借助最少的更改来运行相同的代码,在数据 / 模型缩放时检查内存配置文件; 如果要将一种 ML 算法与另一种 ML 算法进行比较,请让整体代码的结构和流程尽可能相同以减少混乱。最好只更改 estimator 类并对比内存配置文件; 数据和模型 I / O(导入语句,磁盘上的模型持久性)在内存占用方面可能会出乎意料地占主导地位,具体取决于建模方案,优化时切勿忽略这些; 出于相同原因,请考虑比较来自多个实现 / 程序包的同一算法的内存配置文件(例如 Keras、PyTorch、Scikitlearn)。如果内存优化是主要目标,那么即使在功能或性能上不是最佳,也必须寻找一种占用最小内存且可以满意完成工作的实现方式; 如果数据 I / O 成为瓶颈,请探索更快的选项或其他存储类型,例如,用 parquet 文件和 Apache Arrow 存储替换 Pandas CSV。可以看看这篇文章:
《How fast is reading Parquet file (with Arrow) vs. CSV with Pandas?》
https://towardsdatascience.com/how-fast-is-reading-parquet-file-with-arrow-vs-csv-with-pandas-2f8095722e94
Scalene 能做的其他事
在本文中,仅讨论了内存分析的一小部分,目光放在了规范机器学习建模代码上。事实上 Scalene CLI 也有其他可以利用的选项:
仅分析 CPU 时间,不分析内存; 仅使用非零内存减少资源占用; 指定 CPU 和内存分配的最小阈值; 设置 CPU 采样率; 多线程并行,随后检查差异。
最终验证(可选)
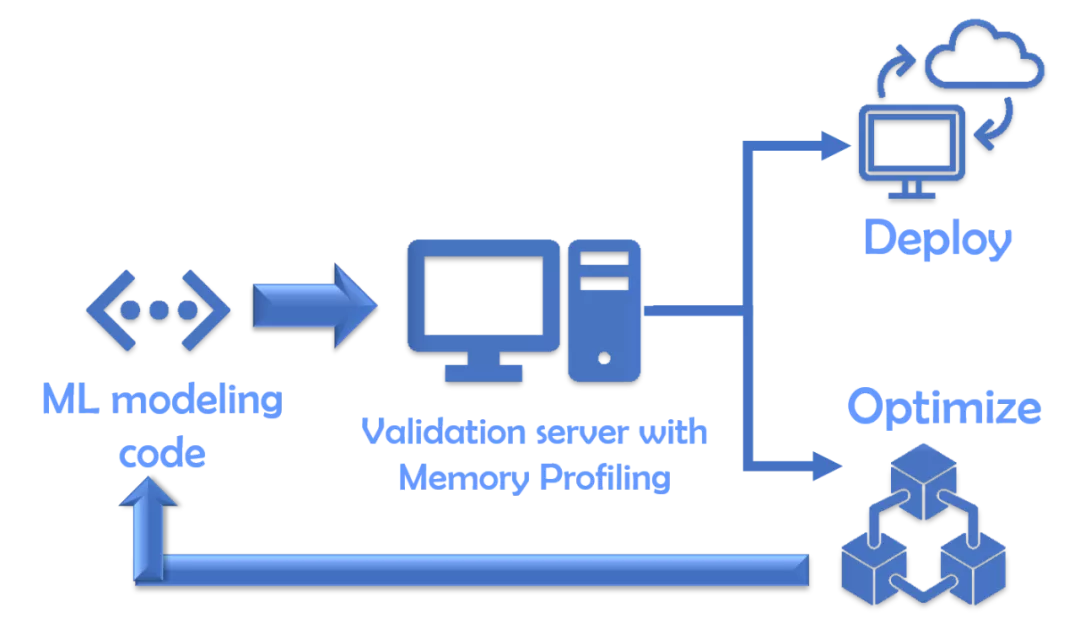
在资源较少的情况下,你最好托管一个验证环境 / 服务器,该服务器将接受给定的建模代码(如已开发),并通过这样的内存分析器运行它以创建运行时统计信息。如果它通过内存占用空间的预定标准,则只有建模代码会被接受用于进一步部署。
总结
在本文中,我们讨论了对机器学习代码进行内存配置的重要性。我们需要使其更好地部署在服务和机器中,让平台或工程团队能够方便运用。分析内存也可以让我们找到更高效的、面向特定数据或算法的优化方式。
希望你能在使用这些工具和技术进行机器学习部署时能够获得成功。
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录