轻松三步搞定数据统计分析:统计+分析+可视化!
我们都知道,数据是支撑决策的重要依据,于是我们可以看到,几乎所有的产品,都会具有数据统计分析的功能模块。往大了说,比如数据中台;往高端了说,比如数据大屏、数据看板、数据驾驶舱;往本质了说,其实就是数据的统计分析。作为一个非数据型产品经理,或者是初级产品经理,该怎样设计这个功能模块呢?
如果你刚好为此苦恼,不妨试一下我最近研究的这三步曲:统计+分析+可视化!
前言
关于数据统计分析,首先表达一个我蛮认同的观点:
好的数据分析师,要像眼科医生一样:配眼镜可能有很多专业的方法,有很多专业的工具,可在配的过程中,医生纠结的不是自己的理论,而是关注用户看得清不清楚,不断问用户“这样可以吗?这样更清楚吗?再这样试试呢?” —— 接地气的陈老师
相信在工作中,大家经常会碰到一些“孔乙己”式的数据统计分析,一开口就是“xx 指标体系”,再加上一大堆什么“权威的、标准的、BAT 认定的”这之类的修饰词汇。这特么就是典型的虚假数据分析啊,因为这些大多数时候,耗时费力,却没有解决实际问题。
并且这种虚假的数据统计分析,还有它遵循的理论模型:
而真正的数据统计分析,就像太极拳的精髓一样:“只重其义,不重其招,你忘记所有的招式,就练成太极拳了。”(以解决业务问题为根本)
统计
要搞数据的统计分析,那第一步我们得先有数据,也就是数据的统计工作。提起数据统计,那自然绕不开数据埋点。如果你们公司从来没整过埋点这个事,那也不用大费周章,因为界内已经有很多成熟的埋点公司了,例如神策、友盟等等,直接花钱办事就完了,也不贵。
我们今天研究的,是通过埋点,能够获得哪些数据呢?总结下来,大概有这么五类:
埋点获取五类数据
整体概况 用户获取 活跃与留存 事件转化 用户特征
来来来,我们逐个剖析一下,这几类数据,具体都包含什么,以及获取这些数据有啥用。
1. 整体概况
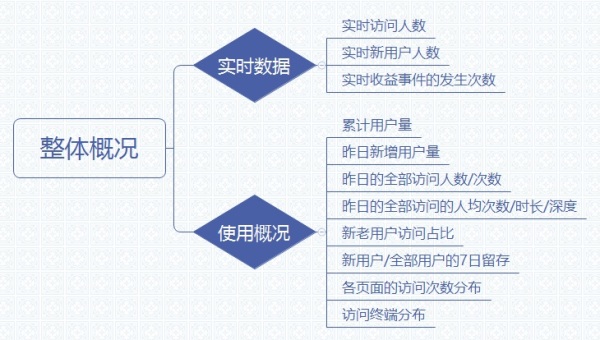
实时数据意义:可以获取到每个小时的产品实时数据,帮助你了解产品目前的实时情况。 使用概况意义:产品整体的使用情况,包括用户量、访问情况、留存等,帮助你对产品整体指标有一个大致的了解。 2. 用户获取
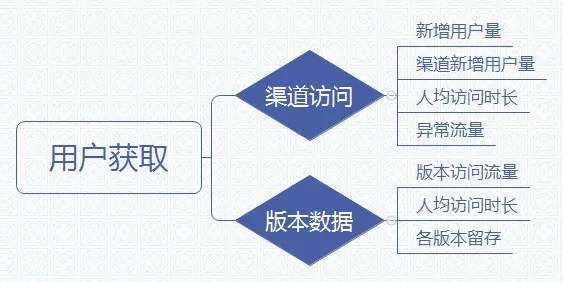
渠道访问意义:每个渠道的用户的使用情况,包括渠道中新用户的占比、留存等,帮助你了解产品在获客层面上的优势与不足。 版本数据意义:每个版本的使用情况,帮助你了解在产品升级的过程中,是否在活跃和留存方面有所改善。 3. 活跃与留存
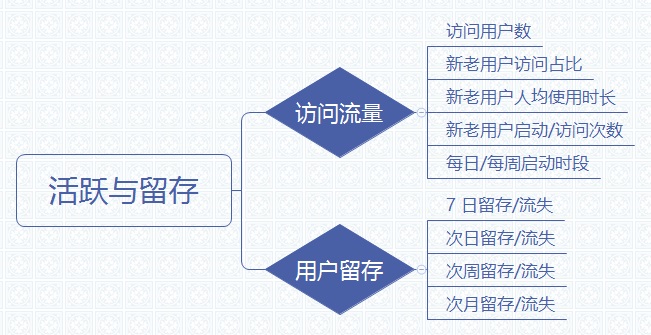
访问流量意义:产品的每日访问数据,指标集中在新老用户的访问行为上,提供访问次数、时长、次数分布、访问时段高峰等指标,帮助了解新老用户在使用产品时的一些行为特征。 用户留存意义:提供用户 7 日,次日,次周,次月留存的数据,帮助你了解新老用户的使用粘性。 4. 事件转化
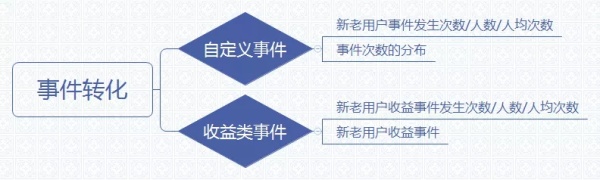
自定义事件意义:用户自定义关键事件,系统会自动生成该事件的发生次数、人数以及分布情况,也就是能够看到用户都在干啥。 收益类事件意义:用户自定义收益类事件,系统会自动生成该事件的发生次数、人数以及分布情况,会根据你选择的数值类型属性,计算该数值的总值、人均值以及次均值。也就是能够看到用户都咋花钱的。 5. 用户特征
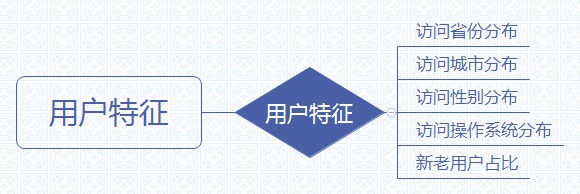
用户特征意义:能够看到我们的用户,都是哪些牛鬼蛇神~ 分析
有了埋点的数据以后,那就是怎样利用这些数据,充分发掘这些数据的价值了。数据分析的套路就更多了,把下面这些学会,应该“二八原则”里面的“八”就能够搞定了~
1. 常见的数据分析指标

综合性指标:反映产品的整体情况。 流程性指标:反映用户的使用行为。 业务性指标:反映具体的业务情况。 2. 常见的数据分析维度

数据细分:通过不同的细分维度分析,往往可以追溯到问题发生的原因,还能为后续的一些动作提供参考依据。 数据对比:没有对比就没有伤害,一方面是横向比较,即自身和别人进行对比,如常见的同比、环比;另一方面是纵向比较,即自身和自身进行对比,比如行业竞品、全站数据、AB 测试等。 3. 常见的数据分析方法
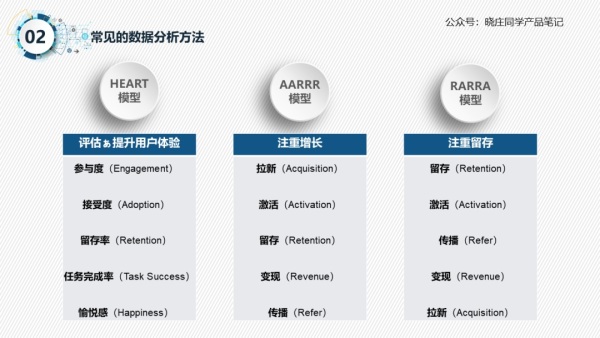
HEART 模型:Google HEART 模型的提出,可以让大家反思自己的产品设计思维,同时运用相关设计工具去提高 HEART 五项指标来完善用户体验,打造更好的产品。
AARRR 模型:该模型出自于《增长黑客》,它是在 2007 提出,当年的获客成本还比较低廉,而这种模型很简单又很直观地突出了增长的所有重要元素,所以这个模型很长时间内都很受欢迎。RARRA 模型:而现在获客的成本与日俱增,市场情况和 2007 年已经完全不同。现在黑客增长的真正关键在于用户留存,而不是获客。于是,一个突出了用户留存重要性的模型 RARRA 诞生了。
可视化
有了统计的数据以及分析的维度之后,最后一步工作就是可视化啦!
而想要完成这一步,又快又好的方法,那自然就是参考各种规范啦,首先我们可以去一个叫做「e-charts」的网站,去查看各种可视化图表,因为开发很多时候,就是依照这些开源的图表库进行撸代码的~
而我们设计的时候,就需要借助各种原型组件啦。数据可视化的内容有很多,我们来举几个典型例子:
1. 折线图
注意事项:选用的线型要相对粗些,线条一般不超过 5 条,不使用倾斜的标签,纵坐标轴一般刻度从 0 开始。预测值的线条线型改为虚线。
2. 柱形图
注意事项:同一数据序列使用相同的颜色。不使用倾斜的标签,纵坐标轴一般刻度从 0 开始。一般来说,柱形图最好添加数据标签,如果添加了数据标签,可以删除纵坐标刻度线和网格线。
3. 条形图
注意事项:同一数据序列使用相同的颜色。不使用倾斜的标签,最好添加数据标签,尽量让数据由大到小排列,方便阅读。
4. 饼图
注意事项:把数据从 12 点钟的位置开始排列,最重要的成分紧靠 12 点钟的位置。数据项不要太多,保持在 6 项以内,不使用爆炸式的饼图分离。不过可以将某一片的扇区分离出来,前提是你希望强调这片扇区。
饼图不使用图例,不使用 3D 效果,当扇区使用颜色填充时,推荐使用白色的边框线,具有较好的切割感。
5. 其他
这种数据可视化的图表还有很多,而它的意义就在于,用图表代替大量堆砌的数字,有助于阅读者更形象直观地看清楚问题和结论。我也在工作中搜集到了一些不错的数据可视化原型组件,有需要的同学可以自行下载啦~
结语
好了,以上就是今天的所有内容了,正如前言所说的,我们今天只讨论武功招式,不讨论内功心法。
延伸一下:数据统计分析,最终还是要从业务中来,到业务中去,一切的形式,都是次要的,关键还是要以解决业务问题为根本、但对于我们这些“新手”来说,经验主义自然也是要借鉴的!相信今天总结的内容,也足够支撑大家比葫芦画瓢啦。
最后再重申一下,想要数据可视化原型组件的同学,可以自行在附件下载啦~
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录