Pandas 中实现聚合统计,有几种方法?
pandas是当前Python数据分析中最为重要的工具,其提供了功能强大且灵活多样的API,可以满足使用者在数据分析和处理中的多种选择和实现方式。今天本文以Pandas中实现分组计数这个最基础的聚合统计功能为例,分享多种实现方案,最后一种应该算是一个骚操作了……
这里首先给出模拟数据集,不妨给定包括如下两列的一个dataframe,需求是统计各国将领的人数。应该讲这是一个很基础的需求,旨在通过这一需求梳理pandas中分组聚合的几种通用方式。
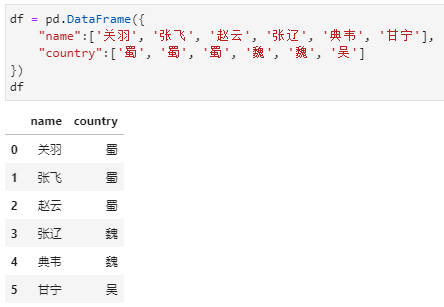
value_counts上述需求是统计各国将领的人数,换言之就是在上述数据集中统计各个国家出现的次数。所以实现这一目的只需简单的对国家字段进行计数统计即可:
当然,以上实现其实仅适用于计数统计这种特定需求,对于其他的聚合统计是不能满足的。
groupby+count第一种实现算是走了取巧的方式,对于更为通用的聚合统计其实是不具有泛化性的,那么pandas中标准的聚合是什么样的呢?对于上述仅有一种聚合函数的例子,在pandas中更倾向于使用groupby直接+聚合函数,例如上述的分组计数需求,其实就是groupby+count实现。
进一步的,其具体实现形式有两种:
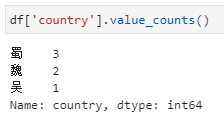
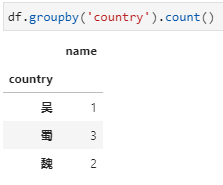
1、分组后对指定列聚合,在这种形式中依据country分组后只提取name一列,相当于每个country下对应了一个由多个name组成的series,而后的count即为对这个series进行count。
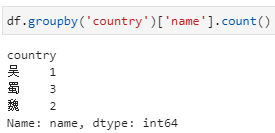
2、分组后直接聚合,然后再提取指定列。此时,依据country分组后不限定特定列,而是直接加聚合函数count,此时相当于对列都进行count,此时得到的仍然是一个dataframe,而后再从这个dataframe中提取对特定列的计数结果。
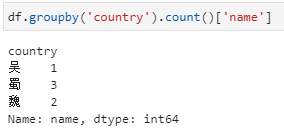
值得指出,在此例中country以外的其他列实际上也是只有name一列,但与第一种形式其实也是不同的,具体在于未加提取name列之前,虽然也是只有name一列,但却还是一个dataframe:
groupby+agg上述方法是直接使用groupby+相应的聚合函数,这种聚合统计方法简单易懂,但缺点就是仅能实现单一的聚合需求,对于有多种聚合函数的情况是不适用的。此时,功能更为强大的agg函数随之登场。agg是aggregation的缩写,可见其是专门用于聚合统计的,其可以接收多种不同的聚合函数,因而更具可定制性。
agg函数主要接收两个参数,第一个参数func用于接收聚合算子,可以是一个函数名或对象,也可以是一个函数列表,还可以是一个字典,使用方法很是灵活;第二参数axis则是指定聚合所沿着的轴向,默认是axis=0,即沿着行的方向对列聚合。agg的函数文档如下:

这里,仍然以上述分组计数为例,讲解groupby+agg的三种典型应用方式:
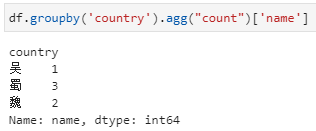
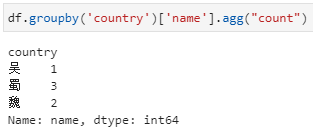
1、agg内接收聚合函数或聚合函数列表。具体实现形式也分为两种,与前面groupby直接+聚合函数的用法类似。实际上,该种用法其实与groupby直接+聚合函数极为类似。
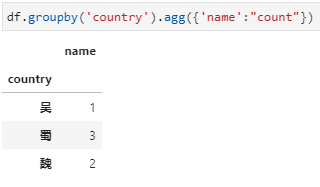
2、agg内接收聚合函数字典,其中key为列名,value为聚合函数或函数列表,可实现同时对多个不同列实现不同聚合统计。这里字典的key是要聚合的name字段,字典的value即为要用的聚合函数count,当然也可以是包含count的列表的形式。用字典传入聚合函数的形式下,统计结果都是一个dataframe,更进一步的说当传入字典的value是聚合函数列表时,结果中dataframe的列名是一个二级列名。
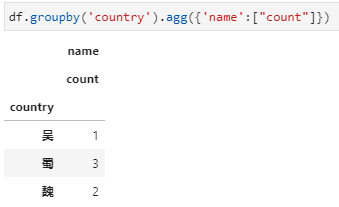
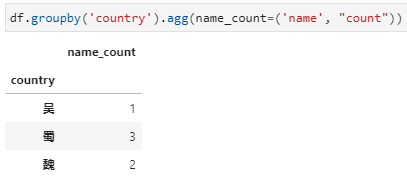
3、agg内接收新列名+元组,实现对指定列聚合并重命名。对于聚合函数不是特别复杂而又希望能同时完成聚合列的重命名时,可以选用此种方式,具体传参形式实际上采用了python中可变字典参数**kwargs的用法,其中字典参数中的key是新列名,value是一个元组的形式,包括聚合字段列名和聚合函数。
groupby+apply如果说上述实现方式都还是pandas里中规中矩的聚合统计,那么这一种方式则是不是该算是一种骚操作?实际上,这是应用了pandas中apply的强大功能,具体可参考历史推文Pandas中的这3个函数,没想到竟成了我数据处理的主力。
由于apply支持了多种重载方法,所以对于分组后的grouped dataframe应用apply,也可实现特定的聚合函数统计功能。首先看如下实际应用:
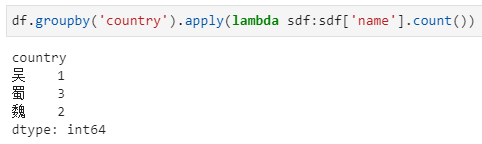
在上述方法中,groupby(country)后的结果,实际上是得到了一个DataFrameGroupBy对象,实际上是一组(key, value)的集合,其中每个key对应country列中的一种取值,每个value为该key对应的一个子dataframe,具体拆解打印如下:

而后,groupby后面接的apply函数,实质上即为对每个分组下的子dataframe进行聚合,具体使用何种聚合方式则就看apply中传入何种参数了!
总结本文针对一个最为基础的聚合统计场景,介绍pandas中4类不同的实现方案,其中第一种value_counts不具有一般性,仅对分组计数需求适用;第二种groupby+聚合函数,是最为简单和基础的聚合统计,仅适用于单一聚合函数的需求;第三种groupby+agg,具有灵活多样的传参方式,是功能最为强大的聚合统计方案;而第四种groupby+apply则属于是灵活应用了apply的重载功能,可以用于完成一些特定的统计需求。
最后,虽然本文以简单的分组计数作为讲解案例,但所提到的方法其实是能够代表pandas中的各种聚合统计需求。
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录