不是所有图像都值16×16个词,清华与华为提出动态ViT
本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
在NLP中,Transformer以自注意力模型机制为法宝,在图像识别问题上的成功已经很广泛了。
尤其是,ViT在大规模图像网络上性能特别高,因此应用特别广。
但随着数据集规模的增长,会导致计算成本急剧增加,以及自注意力中的tokens数量逐渐增长!
最近,清华自动化系的助理教授黄高的研究团队和华为的研究人员另辟蹊径,提出了一种Dynamic Vision Transformer (DVT),可以自动为每个输入图像配置适当数量的tokens,从而减少冗余计算,显著通过效率。
该文以《Not All Images are Worth 16×16 Words: Dynamic Vision Transformers with Adaptive Sequence Length》为标题,已发表在arXiv上。
提出动态ViT
很明显,当前的ViT面临计算成本和tokens数量的难题。
为了在准确性和速度之间实现最佳平衡,tokens的数量一般是 14×14/16×16的。
研究团队观察到:
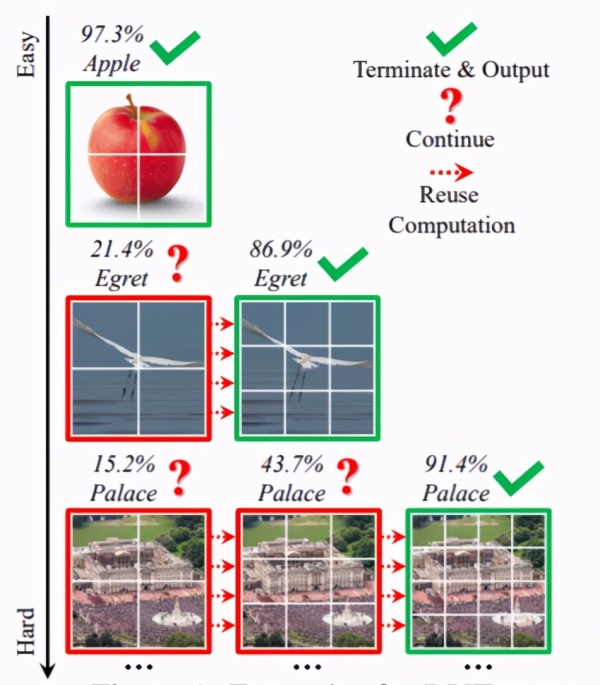
一般样本中会有很多的“简单”图像,它们用数量为 4×4 标记就可以准确预测,现在的计算成本( 14×14)相当于增加了8.5倍,而其实只有一小部分“困难”的图像需要更精细的表征。
通过动态调整tokens数量,计算效率在“简单”和 “困难”样本中的分配并不均匀,这里有很大的空间可以提高效率。
基于此,研究团队提出了一种新型的动态ViT(DVT )框架,目标是自动配置在每个图像上调节的tokens数量 ,从而实现高计算效率。
这种DVT被设计成一个通用框架。
在测试时间时,这些模型以较少的tokens 开始依次被激活。
一旦产生了充分置信度的预测,推理过程就会立即终止。
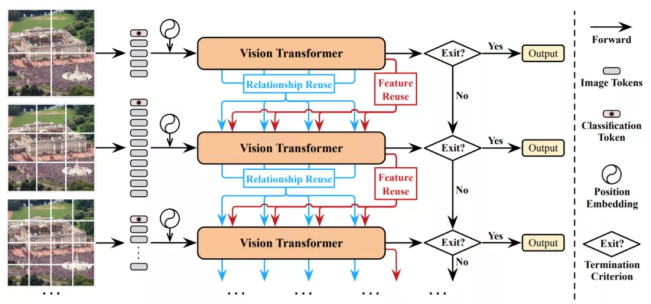
模型的主体架构采用目前最先进的图像识别Transformer,如ViT、DeiT和T2T-ViT,可以提高效率。
这种方法同时也具有很强的灵活性。
因为DVT的计算量可以通过简单的提前终止准则进行调整。
这一特性使得DVT适合可用计算资源动态变化,或通过最小功耗来实现给定性能的情况。
这两种情况在现实世界的应用程序中都是普遍存在的,像搜索引擎和移动应用程序中都经常能够看到。
根据上面的流程图,仔细的读者还会发现:
一旦从上游往下游计算无法成功的时候,就会采取向先前信息或者上游信息进行重用的方法实现进一步数据训练。
研究团队在此基础上,还进一步提出了特征重用机制和关系重用机制,它们都能够通过最小化计算成本来显著提高测试精度,以减少冗余计算。
前者允许在先前提取的深度特征的基础上训练下游数据,而后者可以利用现有的上游的自注意力模型来学习更准确的注意力。
这种对“简单”“困难”动态分配的方法,其现实效果可以由下图的实例给出说明。
那么,接下来让我们来看看这两种机制具体是怎么做的?
特征重用机制
DVT中所有的Transformer都有一个共同的目标:提取特征信号来实现准确的识别。
因此,下游模型应该在之前获得的深度特征的基础上进行学习,而不是从零开始提取特征。
在上游模型中执行的计算对其自身和后续模型都有贡献,这样会使模型效率更高。
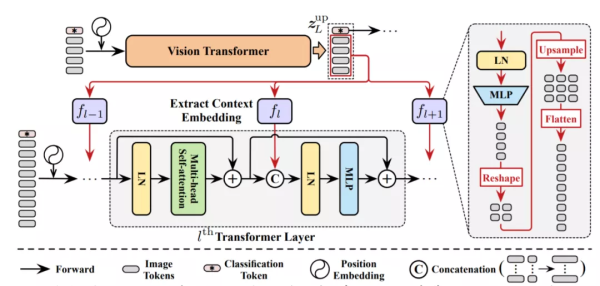
为了实现这个想法,研究团队提出了一个特征重用机制。
简单来说,就是利用上游Transformer最后一层输出的图像tokens,来学习逐层的上下文嵌入,并将其集成到每个下游Transformer的MLP块中。
 关系重用机制
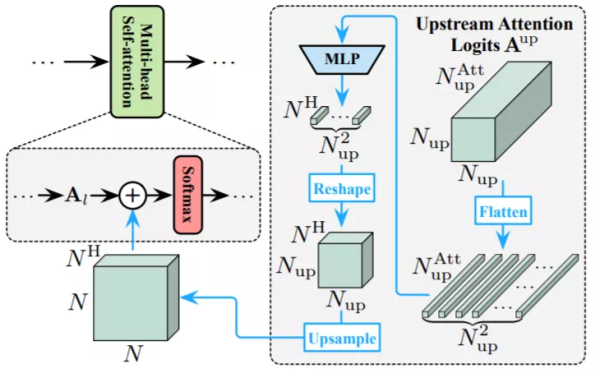
关系重用机制
Transformer的一个突出优点是:
自注意力块能够整合整个图像中的信息,从而有效地模型化了数据中的长期依赖关系。
通常,模型需要在每一层学习一组注意力图来描述标记之间的关系。
除了上面提到的深层特征外,下游模型还可以获得之前模型中产生的自注意力图。
研究团队认为,这些学习到的关系也能够被重用,以促进下游Transformer学习,具体采用的是对数的加法运算。
 效果如何?
效果如何?
多说无益,让我们看看实际效果如何?
在ImageNet上的 Top-1准确率v.s.计算量如下图。
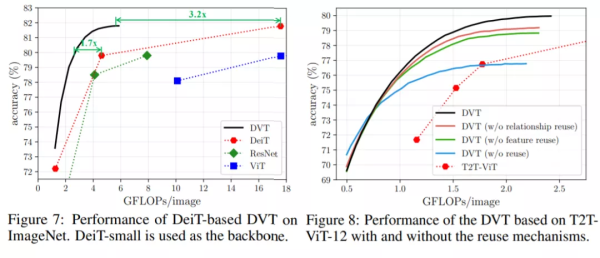
可以看出,DVT比DeiT和T2T-VIT计算效率要显著更好:
当计算开销在0.5-2 GFLOPs内时,DVT的计算量比相同性能的T2T-ViT少了1.7-1.9倍。
此外,这种方法可以灵活地达到每条曲线上的所有点,只需调整一次DVT的置信阈值即可。
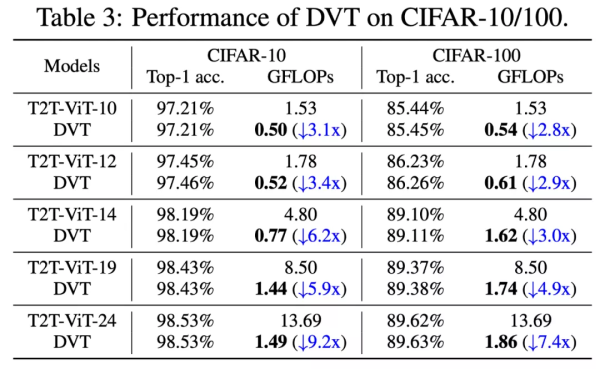
CIFAR的 Top-1 准确率 v.s. GFLOP 如下图。
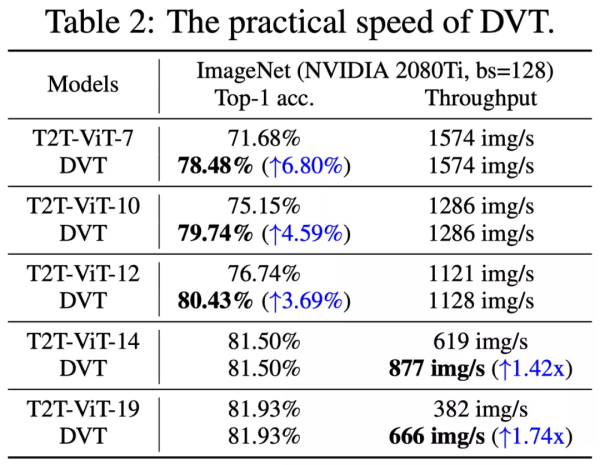
在ImageNet上的 Top-1准确率v.s.吞吐量如下表。
在DVT中,“简单”和 “困难”的可视化样本如下图。

从上面ImageNet、CIFAR-10 和 CIFAR-100 上的大量实证结果表明:
DVT方法在理论计算效率和实际推理速度方面,都明显优于其他方法。
看到这样漂亮的结果,难道你还不心动吗?
有兴趣的小伙伴欢迎去看原文哦~
传送门
论文地址:
https://arxiv.org/abs/2105.15075
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录