详解 Pandas 与 Lambda 结合进行高效数据分析
这篇文章小编来讲讲lambda方法以及它在pandas模块当中的运用,熟练掌握可以极大地提高数据分析与挖掘的效率
导入模块与读取数据
我们第一步需要导入模块以及数据集
import pandas as pd df = pd.read_csv(“IMDB-Movie-Data.csv”) df.head() 创建新的列
一般我们是通过在现有两列的基础上进行一些简单的数学运算来创建新的一列,例如
df[AvgRating] = (df[Rating] + df[Metascore]/10)/2
但是如果要新创建的列是经过相当复杂的计算得来的,那么lambda方法就很多必要被运用到了,我们先来定义一个函数方法
def custom_rating(genre,rating): if Thriller in genre: return min(10,rating+1) elif Comedy in genre: return max(0,rating-1) elif Drama in genre: return max(5, rating-1) else: return rating
我们对于不同类别的电影采用了不同方式的评分方法,例如对于“惊悚片”,评分的方法则是在“原来的评分+1”和10分当中取一个最小的,而对于“喜剧”类别的电影,则是在0分和“原来的评分-1”当中取一个最大的,然后我们通过apply方法和lambda方法将这个自定义的函数应用在这个DataFrame数据集当中
df[“CustomRating”] = df.apply(lambda x: custom_rating(x[Genre], x[Rating]), axis = 1)
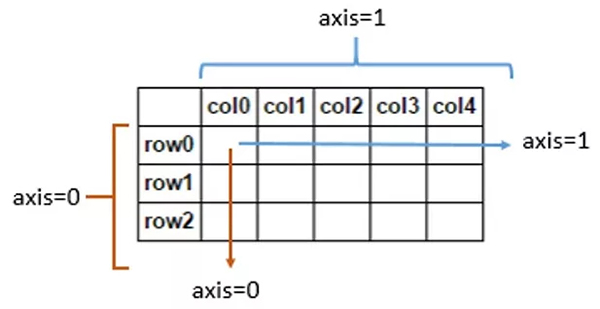
我们这里需要说明一下axis参数的作用,其中axis=1代表跨列而axis=0代表跨行,如下图所示
筛选数据
在pandas当中筛选数据相对来说比较容易,可以用到& | ~这些操作符,代码如下
# 单个条件,评分大于5分的 dfdf_gt_5 = df[df[Rating]>5] # 多个条件: AND – 同时满足评分高于5分并且投票大于100000的 And_df = df[(df[Rating]>5) & (df[Votes]>100000)] # 多个条件: OR – 满足评分高于5分或者投票大于100000的 Or_df = df[(df[Rating]>5) | (df[Votes]>100000)] # 多个条件:NOT – 将满足评分高于5分或者投票大于100000的数据排除掉 Not_df = df[~((df[Rating]>5) | (df[Votes]>100000))]
这些都是非常简单并且是常见的例子,但是要是我们想要筛选出电影的影名长度大于5的部分,要是也采用上面的方式就会报错
df[len(df[Title].split(” “))>=5]
output
AttributeError: Series object has no attribute split
这里我们还是采用apply和lambda相结合,来实现上面的功能
#创建一个新的列来存储每一影片名的长度 df[num_words_title] = df.apply(lambda x : len(x[Title].split(” “)),axis=1) #筛选出影片名长度大于5的部分 new_df = df[df[num_words_title]>=5]
当然要是大家觉得上面的方法有点繁琐的话,也可以一步到位
new_df = df[df.apply(lambda x : len(x[Title].split(” “))>=5,axis=1)]
例如我们想要筛选出那些影片的票房低于当年平均水平的数据,可以这么来做。
我们先要对每年票房的的平均值做一个归总,代码如下
year_revenue_dict = df.groupby([Year]).agg({Revenue(Millions):np.mean}).to_dict()[Revenue(Millions)]
然后我们定义一个函数来判断是否存在该影片的票房低于当年平均水平的情况,返回的是布尔值
def bool_provider(revenue, year): return revenue
然后我们通过结合apply方法和lambda方法应用到数据集当中去
new_df = df[df.apply(lambda x : bool_provider(x[Revenue(Millions)], x[Year]),axis=1)]
我们筛选数据的时候,主要是用.loc方法,它同时也可以和lambda方法联用,例如我们想要筛选出评分在5-8分之间的电影以及它们的票房,代码如下
df.loc[lambda x: (x[“Rating”] > 5) & (x[“Rating”] < 8)][[“Title”, “Revenue (Millions)”]] 转变指定列的数据类型
通常我们转变指定列的数据类型,都是调用astype方法来实现的,例如我们将“Price”这一列的数据类型转变成整型的数据,代码如下
df[Price].astype(int)
会出现如下所示的报错信息
ValueError: invalid literal for int() with base 10: 12,000
因此当出现类似“12,000”的数据的时候,调用astype方法实现数据类型转换就会报错,因此我们还需要将到apply和lambda结合进行数据的清洗,代码如下
df[Price] = df.apply(lambda x: int(x[Price].replace(,, )),axis=1) 方法调用过程的可视化
有时候我们在处理数据集比较大的时候,调用函数方法需要比较长的时间,这个时候就需要有一个要是有一个进度条,时时刻刻向我们展示数据处理的进度,就会直观很多了。
这里用到的是tqdm模块,我们将其导入进来
from tqdm import tqdm, tqdm_notebook tqdm_notebook().pandas()
然后将apply方法替换成progress_apply即可,代码如下
df[“CustomRating”] = df.progress_apply(lambda x: custom_rating(x[Genre],x[Rating]),axis=1)
output

当lambda方法遇到if-else
当然我们也可以将if-else运用在lambda自定义函数当中,代码如下
Bigger = lambda x, y : x if(x > y) else y Bigger(2, 10)
output
10
当然很多时候我们可能有多组if-else,这样写起来就有点麻烦了,代码如下
df[Rating].apply(lambda x:”低分电影” if x < 3 else (“中等电影” if x>=3 and x < 5 else(“高分电影” if x>=8 else “值得观看”)))
看上去稍微有点凌乱了,这个时候,小编这里到还是推荐大家自定义函数,然后通过apply和lambda方法搭配使用
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录